RiEMann Pipeline
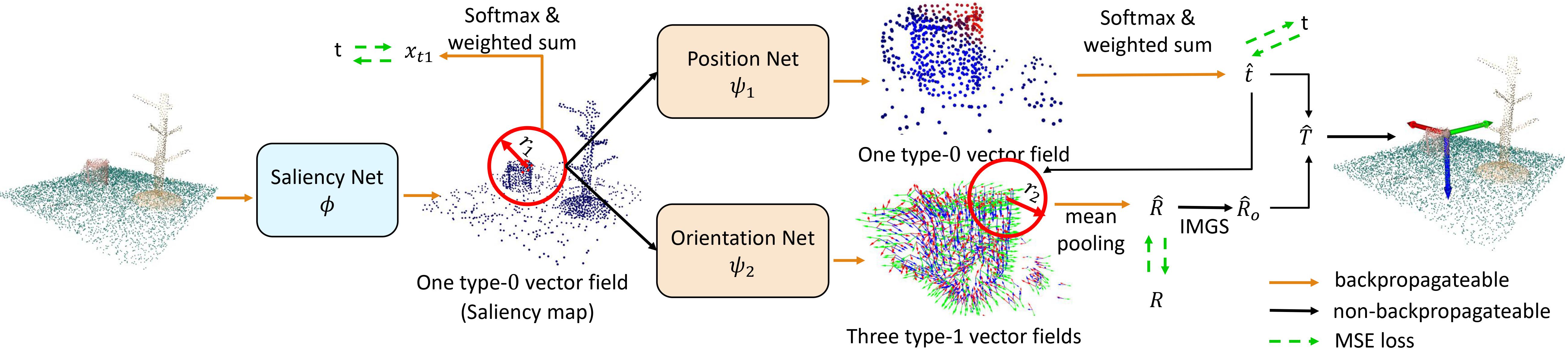
RiEMann models the SE(3)-equivariant action space of robot manipulation tasks as target poses, consisting of a translational vector \( \mathbf{t} \in \mathbb{R}^3 \) and a rotation matrix \( \mathbf{R} \in \mathbb{R}^9 \), which are proven to be SE(3)-equivariant.
For a point cloud input of a scene, a type-0 saliency map is firstly outputted by an SE(3)-invariant backbone \( φ \) to get a small point cloud region \( B_{ROI} \), and an SE(3)-equivariant policy network that contains a translational heatmap network \( ψ_1 \) and an orientation network \( ψ_2 \) predicts the action vector fields on the points of \( B_{ROI} \) . Finally, we perform softmax, mean pooling, and Iterative Modified Gram-Schmidt orthogonalization to get the target action \( T \).